As discussed in the first part of this post, the process of collecting all relevant contracts is critical to a successful Contract Data Management (CDM) implementation and requires careful advance planning to identify the type and location of all relevant contracts.
In this installment, we’ll explore how technology can help gather contracts from various sources while reducing disruption to the enterprise, and then examine how secondary processes driven by human expertise can address common under and over inclusiveness issues arising from that initial collection.
Automating Collections – Methods and Limitations
For large, complex enterprises, deploying the right technology is critical, as overreliance on human effort can be disruptive to stakeholders and time/cost prohibitive. At the same time, technology deployed without the right expertise is unlikely to yield to the desired result.
Where contracts are stored in known repositories (whether formal repositories, VDRs, or other applications), integrations can be created or deployed to automatically push/pull contracts to the CDM database where they can be converted to structured data. This can be done directly on a source-by-source basis, or potentially through an Enterprise Data Management (EDM) provider. In many cases, existing metadata can help isolate contracts in scope for the CDM database, identify and exclude out of scope contracts, or identify contracts that require expedited processing (e.g., top 100 customers by revenue).
Although one might expect collecting from an existing contract repository to be the end of the collection effort, often the output is both under and over-inclusive. First, results will only be as complete as the existing systems (and the collections efforts that preceded them) and other methods may be needed to address gaps. Second, depending on the content of the repository, the output may need to be refined to cull non-contracts (e.g., approvals, negotiation correspondence) and duplicate or near duplicate versions (e.g., unexecuted drafts and negotiation redlines).
And what about contracts stored more diffusely across multiple environments, including in SharePoints, billing and invoicing systems, and/or individual email accounts or OneDrives? Traditionally, finding and collecting contracts from these environments could require significant collective time and effort to identify all custodians and locate the contracts in their custody. While that is still true in many cases, the increasing penetration of EDM and sophistication of enterprise search tools is opening doors to more automated ways of finding contracts across the entire enterprise, reducing the manual burden on stakeholders. Development of ML tuned to accurately identify contracts promises to achieve even better outcomes.
That said, purely automated collections using enterprise search is possible only in unusual circumstances, given significant variation in form and content of contracts within and across industries, to say nothing of varying types of documentation that may reflect or change key contractual terms (e.g., notice letters and emails). Here again, typical results can be expected to be both over-inclusive and under-inclusive.
The following is a useful framework to classify raw search results (and non-results):
- True Positive – Search correctly returns contracts stored in the environment.
- True Negative – Search correctly avoids non-contracts stored in the environment.
- False Positive – Search incorrectly returns non-contracts stored in the environment.
- False Negative – Search does not return contracts stored in the environment.
Obviously, an ideal search would return 100% True Positives, while avoiding both False Positives (which result in over-inclusion) and False Negatives (which result in under-inclusion). But generally, we can expect a tradeoff between return rate (or % of True Positives returned) and confidence (% of search results that are True Positives vs. False Positives). Or in other words, a side effect of achieving a higher return rate tends to be lower confidence level, meaning the price of a complete collection implicates a secondary effort to cull out non-contracts that are swept into the search.
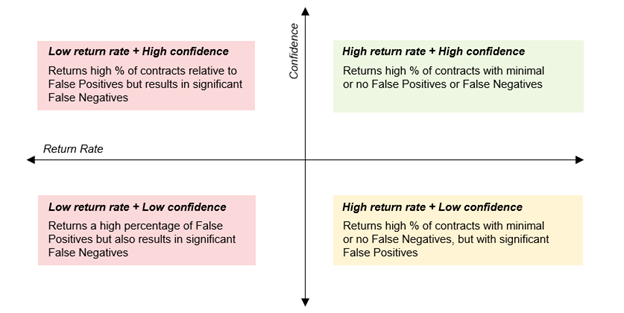
As with collecting from repositories, duplicates and near duplicates can be as much of or more of an issue when collecting across multiple environments (e.g., different stakeholders may have multiple versions of the same contract in their email inboxes or on their hard drives, including duplicates, unsigned drafts, and redlines).
Finally, it’s critical to understand inherent limitations that may result in “baked in” False Negatives even if the search tool otherwise avoids them. For example:
- Contracts in multiple languages – large global enterprises will often execute contracts in a variety of languages. If the enterprise search tool is not tuned to identify contracts in those languages, there will be gaps in collection.
- Non-searchable file formats – contracts stored as images and not searchable text (e.g., non-searchable PDFs or TIFF files) may first need to be converted to searchable PDFs (although other metadata associated with the file may help identify them).
- Paper copies – this one is obvious, but if contracts exist only in paper form, they need to be accounted for elsewhere in the collection pan. This is less common today but can be an issue for certain legacy contracts and/or cases where the execution versions are wet signed and not subsequently converted to PDF.
Refining the Results: Tackling Under and Over Inclusiveness
Since we can expect initial bulk collection and document transfer to be both under and over-inclusive, secondary workstreams are generally needed to (1) isolate relevant contracts from non-relevant contracts and other types of unstructured data, and (2) identify and fill gaps in the collection.
Resolving the over-inclusiveness problem involves removing non-contracts, out of scope contracts, duplicates, and near duplicates (such as drafts and redlines) from the population. This usually requires a mix of technology and technology-enabled human review:
- For example, automatic duplicate detection based on a hash function can identify many duplicates, but it will not by itself identify where one copy of an amendment is collected as a stand-alone file and another is scanned together with a cover letter (a secondary analysis of structured metadata may be needed to resolve such cases).
- Similarly, technology like duplicate detection can be over-deployed. For example, a schedule or bulk amendment may legitimately be replicated in the repository because it is part of the documentation for multiple contract families. In such cases, external metadata needs to be used to avoid over-culling.
Resolving the under-inclusiveness problem requires understanding any gaps in the source repositories and applications, the limitations of the collections technology deployed, and developing strategies to address both. This usually involves a dose of good old-fashioned project management, and may include, for example:
- Outreach to likely contract owners and relationship managers.
- External validation against Accounts Payable/Accounts Receivable system, customer lists, or other records to identify relationships with active contracts not included in the collection results;
- Internal validation of the collected documents. For example, identifying gaps once contracts are grouped into families – i.e., where each contract is mapped to all its ancillary amendments and other documents. We can then determine which families are incomplete (e.g. “orphan” amendments missing the amended contract) or where the executed version of a document is missing.
A deficient collection effort can create critical gaps that affect the integrity of the final structured contract data. However, the right mix of planning, technology, and expertise will pave the way to a complete collections effort and successful CDM implementation.