Expecting More from Data Providers
As we’ve touched on in other posts, contract data insights can be hugely powerful and valuable. Organizations that focus on collecting high-quality data from within their contract portfolio, and that are committed to supporting analytics to influence outcomes, are well-positioned to proactively manage risk, meet obligations, and identify opportunities to capture revenue and margin.

Unfortunately, given the complexity of interpreting contract prose, when it comes to getting high-quality actionable data from their agreements, many companies have resigned themselves to expect too little of contract data providers. However, as the numbers above indicate, there’s simply too much value locked inside of contracts to settle for partial solutions. We must expect more.
Traditionally, companies have trusted ML solutions to identify text accurately across large volumes of documents – something they’ve become very good at. But the expectation typically goes no further. When it comes to data interpretation, it is too difficult for these same systems to provide similarly high levels of specific accuracy, at least in the near-term. However, true legal value hinges on accurate interpretation – not just identification – of contract data points. This is why, if you’re going to go down the “structured contracts data” journey, you need to make sure that you do so with reliably high-quality data, and this is not something tools alone can do (not even great ML tools).
Yes, the tools are part of the solution. But that tooling needs to be complemented by a robust data model design process built to deliver specific, well-defined business insights and a comprehensive quality management program to prevent, identify, and correct bad data.
In this post, we’ll discuss why executing on bad data not only causes you to waste a significant amount of money in acquiring the data but also creates risk and detracts value from the organization. Along the way, we will explore what bad data looks like and what it takes to deliver highly specific data at near-perfect levels of accuracy and inspire confidence in the reliability of that data.
The price of bad data
From fines for failure to make a required notification of a data breach to a missed renewal opportunity, there are many ways that using bad data from contracts can hurt a company’s bottom line.
Take, for example, a company that is looking to improve its working capital (say, in the middle of a pandemic) and wants to change its standard supplier payment terms from Net-60 to Net-90 days. As part of their post-execution process, they use ML to identify the payment terms language in their agreements and store that prose in a database. However, the payment terms data doesn’t include any additional specificity – just the text from the contract. The company can create a list of contracts that have payments terms, but without opening each agreement they will have no way of knowing if a particular contract is already on Net-90 payment terms. Despite having tooling that helps them pull out payment terms language, bad data will force the company to expend additional time and money to find the relevant set of contracts.
As the figures below indicate, the use of bad data isn’t limited to contracts. Companies are drowning in information from corporate applications, social media, and transactional data. Not surprisingly, with so much material, data inaccuracy is at an all-time high, and bad data is resulting in missed sales and wasted resources and expenses.
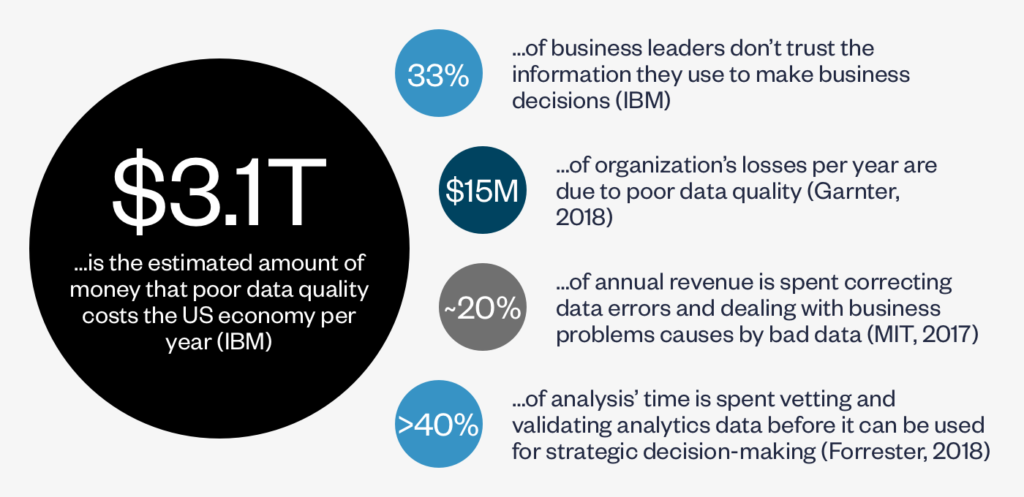
What does bad data look like?
So, what does bad data look like? It’s important to not limit the definition to only inaccurate or erroneous information. It’s much broader than that. Bad data is any information that cannot help your organization to achieve its goals. The following is a look at some of the most common types of poor-quality data.| Definition | Example |
|---|---|
| Inaccurate Data Information that has not been captured correctly. | Governing law is captured as New Jersey when it should be New York. |
| Incomplete or Non-Specific Data Data that lacking in specificity or is not relevant to the business’s objectives. | A business wants to know which contracts, across its portfolio, could be assigned to a 3rd party at the business’s sole discretion. The data model only captures which contracts have an assignment provision and does not indicate (a) who can assign, (b) whether consent is required, or (c) if there are exceptions to the consent requirement. |
| Duplicate Data Capturing the same data multiple times or in slightly different ways. | Several copies or versions (e.g., partially executed and fully executed) of the same contract are uploaded and included in analytics. |
| Invalid Data Capturing data in a way that doesn’t meet defined specifications. | The Effective Date for a subset of contracts is captured using the European date format when an integrated downstream system expects the U.S. date format. |
| Mis-defined Data The substantive definition of the field is wrong relative to the use case looking to be enabled. | Data indicates that a contract has a fixed term of 12 months, but the contract automatically renews following the initial 12-month term. |
What does high-quality data look like?
Sixty-plus years after the expression “garbage in, garbage out” was coined (a term with its own history of bad data), organizations still struggle with data quality. As a result, when data are unreliable, businesses quickly lose faith in the metrics. This lack of faith leads end-users to:- Consume additional resources to validate and remediate data,
- Reject important, counterintuitive implications that emerge,
- Fall back on gut or intuition to make decisions and implement a strategy, and
- Ultimately abandon the analytics platform.
- The bar for considering data to be trustworthy can be incredibly high – oftentimes approaching 100% accuracy – depending on the business criticality of the use case. Mistakes in high visibility fields, even if infrequent, will understandably cause end-users to lose trust in the data.
What does it take to deliver?
So, what does it take to create highly specific data at near-perfect levels of accuracy and inspire confidence in the reliability of that data?- Thoughtful data model design,
- Consistency in interpretation, and
- A comprehensive quality management program.
Thoughtful Data Model Design
The first step to avoid creating bad data is to agree on the data model. As we discussed at length here, well-thought-out data modeling is integral to converting complex legal prose into the high-quality structured data that enable data-based decisions. Working with experienced data model practitioners will help a company avoid running into scenarios like the one below where a technology-only solution provides only some of the information needed to answer the business question at hand.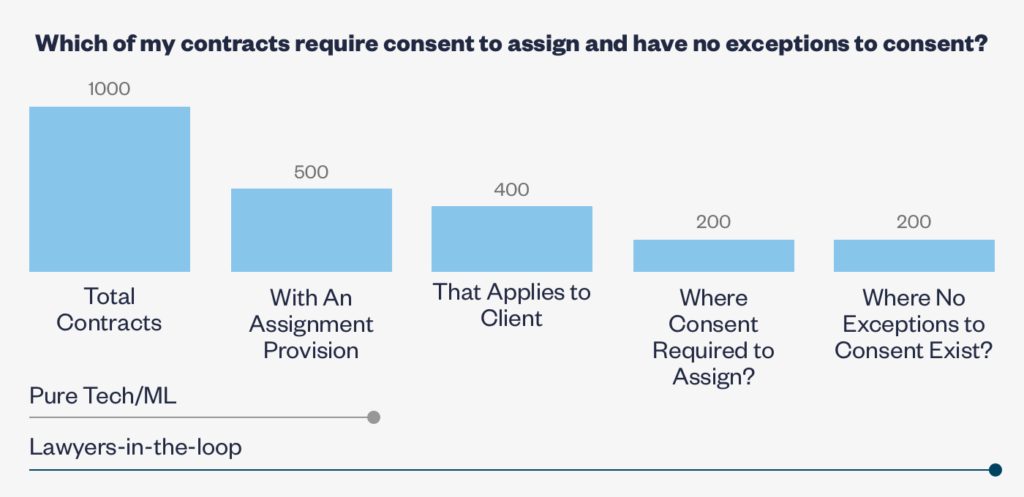
Consistency in Interpretation
Once you have agreed on a data model, to ensure accuracy via consistency, a rigorous program of data calibration, harmonization, and syndication of interpretive guidance is required. Without a syndicated approach, even data extracted and structured consistently by one individual may be considered an error by someone else (even within the same company). Take an example as simple as Expiration Date in a contract that auto-renews. One person might (consistently) extract the date that the initial term expires while someone else (also, consistently) uses the latest possible expiration date of the contract after the parties have used all possible renewals. Without calibrating on interpretation, this sort of inconsistency will wreak havoc on your data. This is why, at the outset of any new client engagement, Knowable undergoes a calibration exercise to create a baseline for quality. This process, which we call gauge testing, aligns our analyses with the substantive guidance and legal judgment of key client stakeholders, highlights possible areas of confusion before work begins, and allows for the early identification of misalignment between the client and Knowable, as well as within the client.| Gauge Test Answers | |||
|---|---|---|---|
| Field | Client | Knowable | Notes from Gauge Test |
| Agreement Start Date The effective date or commencement date of the agreement. In rare instances, if an effective or commencement date is not listed in the contract, users may input the signature date. | 8/1/2020 | 8/1/2020 | Aligned |
| Expiration Date The end date (calculated) or whatever the end date is of the current period. | 7/31/2023 | 7/31/2021 | The client would like to add in the additional renewal term in calculating the end date. In this case, the initial term is 1 year, with an automatic renewal for an additional 2 years. Thus, the end date should be 7/31/2023. |
A Comprehensive Quality Program
A comprehensive contract data quality program should include elements of both prevention and correction. Early in my career, I learned the “1-10-100 Rule” which is a quality management concept developed to quantify the hidden costs of poor quality. The idea is that prevention is less costly than correction which is less costly than failure. The principle is that it makes more sense to invest $1 in prevention than to spend $10 on a correction. That in turn makes more sense than to incur the cost of a $100 failure.- Prevention: A CDM provider should take steps to ensure poor quality data isn’t created in the first place. The right solution will have a methodology and tooling in place to cut off likely problem areas before they can even get into the hands of end-users. Knowable’s quality program primarily relies on (a) intelligent data modeling as we discussed above and (b) tooling that prevents the creation of poor-quality data (e.g., by restricting non-conforming data from being entered and requiring additional data entry for interdependent fields).
- Correction: Once bad contract data makes its way into business applications, it needs to be identified, documented, and fixed to ensure that executives, data analysts, and other end-users are working with good information. The corrective component of a quality program should include both a methodical approach for targeting known and potential problem areas as well as a statistically supported accuracy validation. Knowable’s uses a series of comprehensive logic tests to find and correct common errors in the data and a multi-gate statistical random sampling process (which allows us to make our 98% data accuracy guarantee).
Mike Hagemann is VP of Solution Architecture, responsible for overseeing the design and pricing of Knowable’s solutions. Previously, Mike was Director of Solution Engineering at Axiom, leading the design and deployment of that company’s solutions portfolio. Before that, Mike filled numerous leadership roles at Axiom ranging from Project Management and Technology to HR and Recruiting. Mike holds a law degree from The John Marshall Law School as well as an undergraduate degree in Biomedical Engineering from The University of Iowa.