
Large Language Models (LLMs) fall within the broader category of machine learning, which are Artificial Intelligence (AI) models generally distinguished as being able to perform a task without explicitly being programmed to do so. Instead, these models are typically trained on data relevant to the task with the goal of applying the models to similar tasks in the future.
While there are many similarities between LLMs and earlier versions of machine learning models (and other algorithms), LLMs do have unique characteristics, such as:
A huge volume of training data
Typically, the data populations used to train LLMs are massive, often spanning most, if not all, of the internet, enabling the identification of the most common patterns at scale. This data then informs training criteria, characteristics, and features. The word “large” in describing the model often means features that reach a volume of billions or even trillions, as distinguished from other language models.
Incorporation of context
The “language” component refers to the model’s ability to predict the human language to determine whether a word or letter is likely to appear in a given sentence or other related context. For example, given the beginning of the sentence: “I am going to drive a ____,” the blank is far more likely to be populated by the word “car” than it is to be populated by the word “fish” because “car” is the most probabilistic deduction. Or take another example: “I am going to read a ___” is likely to be populated by “book” rather than “computer.” As with other AI models, this likelihood is determined based on the training data.
In many common natural language expressions, sequences of words and sentences make far more sense in terms of having a coherent meaning, and computers can determine these based on the training data. As a result, LLMs can make predictions that mimic an understanding of the semantic meaning associated with words in the same sentence.
More out-of-box applications
As a result of the above, there is no need to train or refine the algorithms for some use cases, as they generalize well to a range of situations sufficiently similar to the large training sets involved.
Use Case Examples of Large Language Models
The primary use case of LLMs in the recent press has been related to Generative AI (GAI), specifically drafting various types of text documents or conducting conversations. Adjusting our examples above to the context of the legal profession, we can imagine that within the phrase, “This contract cannot be assigned without ____,” the next word is far more likely to be something like “consent” than it is to be something like “courage.”
As with other algorithms, LLM functionality can be re-purposed to a much broader range of use cases than one may think. Just as generative AI can help with drafting an email or a blog post (not this one 😊), it can also perform summarization tasks as well. For example, if provided an email or blog post and prompted to “please summarize the following text in a few sentences,” the result will often be a sufficient summary that the user can use “as-is” or edit quickly.
Given these capabilities, it makes sense that people would be excited about applying LLMs to the legal domain. After all, in the legal field, many required tasks involve large volumes of written text, including legal research, drafting a legal memo or a contract, contract review, court reporting, and so on. When properly applied, LLMs can help with the heavy lifting. If not, it can have embarrassing consequences—remember the lawyer who used ChatGPT to write a motion?
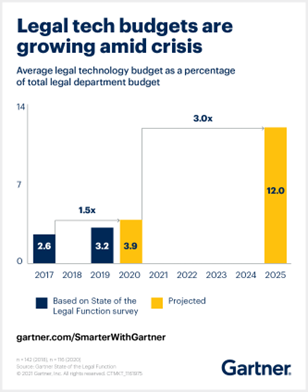
In parallel, the historical means of performing a great deal of legal work has been very manual and inefficient (e.g., throwing a bunch of expensive associates at a problem or less expensive but not cheap professionals). There’s been increasing market pressure for efficiency gains, prompting legal departments to increase their spending on legal technology threefold by 2025.
Net of these considerations, the excitement around LLMs has been brought on by:
- An ongoing need for efficiency and cost reduction, combined with
- A perception that there may finally be a simpler, faster, and cheaper way to meet these efficiency goals.
NB: This is not the first type we’ve seen this level of excitement.
In 2017-2018, there was already quite a bit of hype that AI would completely revolutionize if not wholly automate, legal workflows. In practice, the results were much more modest. Other forms of technology have had similar hype cycles (remember Blockchain?) but failed to deliver on these promises.
Why, you may ask? Turns out, it was never as simple as the industry thought. In the next series post, we’ll discuss the complexity of applying LLMs and AI to contracts, which will help explain the disconnect between the hype cycle and the results. Stay tuned.