
This blog post is the first in a series of articles setting out what Contract Data Management (CDM) is and how it differs from, but also complements traditional Contract Lifecycle Management (CLM) in powerful ways.
Today’s post describes how and why extracting the most value from enterprise contracts is now in many ways more about post-execution CDM than improving the negotiation process itself. And why, in that post-execution realm, value creation opportunities stem primarily from achieving usable transparency across an organization’s contracts portfolio –something CDM is uniquely well-suited for.
The next blog post in this series will look at the distinctive capabilities required for effective CDM, how these differ most CLMs’ core competencies, but also how they can supplement them in powerfully synergistic ways .
Later posts will investigate in more detail how CDM can be a key to successful CLM implementation, by mitigating some of the most common CLM deployment challenges while also significantly augmenting the potential for CLMs to deliver strong outcomes.
Finally, this series will explore how CDM can help enterprises adopt the “right tool for each job” –that is, the combination of contracts capabilities, whether CLM or ‘point solutions’, best suited to each business’ specific needs, even where those needs diverge across the organization and are best served by having different toolsets set against different tasks.
Why CDM matters – The power of answering questions at enterprise scale
First, let’s remind ourselves: What are contracts really for? Historically, they were mainly a “passive” asset. A memorialization of mutual intent at the time parties to a transaction engaged in it. That formal recording needed to exist so that, combined with a (hopefully) reliable court system, the parties had enough protection in case things didn’t go as planned that they were willing to enter into the arrangement in the first place.
As a result, contracts were pieces of paper which, once executed, could be safely locked away in a filing cabinet and left there until such time as things did, in fact, fail to unfold as intended.
Fast forward to today: the level of competition and pace of change in business have ramped up dramatically. Regulators are increasingly active and prescriptive. Scale efficiencies are harder and harder to come by as customers demand more and more tailored solutions.
In other words, to stay competitive, businesses need to extract every last bit of value from each and every one of their commercial relationships.
The good news? Every commercial relationship starts with, and is defined by, a contract.
The bad news? For the most part, even today, contracts continue to be little more than unusable prose lost to irrelevancy as soon as the last signature was affixed (or even sooner in many cases, as we find that a surprisingly large percentage of the contracts uploaded by our customers do not, in fact, include signatures from both parties!)
So this, then, is the fundamental transformation of modern contracting: contracts have become an “active” value-creation asset that companies can mine to stay ahead of the competition.
Whether that takes place through revenue-enhancement initiatives (e.g., pricing terms or time-to-revenue optimization), cost reduction efforts (e.g., procurement spend reduction), or better compliance with ever expanding regulatory requirements (e.g., data privacy, infosec, employment), the information buried in contracts is the key to unlocking critical pockets of value.
This is where CDM comes into play, turning contracts into critical business data. CDM both supplements and enhances traditional CLM. The latter has historically focused on contracts as documents, typically targeting improvements in the workflow involved in creating and negotiating these. CDM in turn thinks of each element in a contract as a data point, which allows for the contract to become usable as a source of business truth, not just a workflow tool.
Why does that matter? In short, because value in contracts is unlocked by answering questions at scale across large numbers of documents, as opposed to within any one individual agreement.
Having access to a document repository, even a searchable one with key words extracted and indexed, allows you to answer questions only one document at a time. For instance: Are there any exclusivity provisions in the Acme contract? When does it expire? Does it auto-renew? Can we terminate it for convenience?
So if you already know which document you should be looking at, and you have the time and ability to interpret the prose it contains, a document repository will allow you to answer the question.
On the other hand, what if –as is more often the case—you first need to figure out which of your tens of thousands of contracts are relevant to any given question? Document repositories don’t allow you to look ‘across’ contracts (or clauses) to be able to do this.
That’s because delivering usable data isn’t the same thing as merely surfacing text: it involves instead reporting on that that text means in a standardized format that allows for comparison across agreements –ideally, the company’s entire portfolio.
Absent that capability, you need to open every document to figure out whether it is in fact responsive to the question being asked. That’s massively expensive and time consuming. By contrast, a structured contract data repository will allow you to answer such questions in –literally—seconds (and with Knowable’s solution, with just a few clicks).
Let’s quickly ground this in a couple of real-life examples. First, let’s look at how things play out when trying to answer a question about a single document:
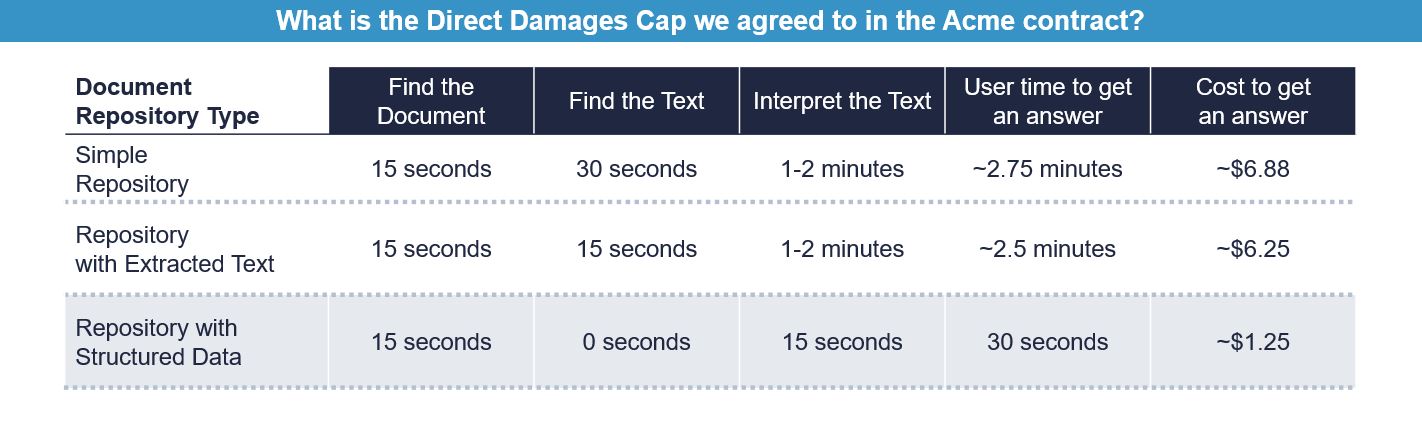
Here, having access to a structured data repository allows you to answer the question in about 1/5th of the time, for about 1/5th of the cost of doing the same with a document repository. That’s fairly compelling, but perhaps not enough to justify on its own the extra cost of building out a structured contract data repository in the first place.
Consider this alternative scenario, however:
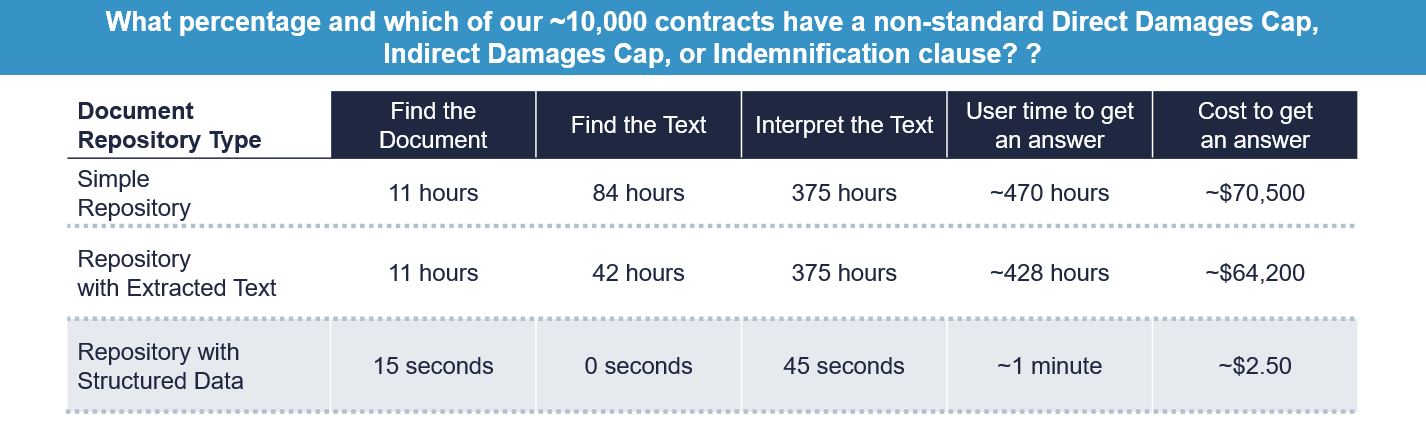
Here, both the cost and time difference to answer the question are on the order of 30,000:1. Yet these are exactly the types of questions that legal departments are asked to answer every day, whether as the result of regulatory inquiries, litigation, questions from business partners –or, more to the point, what is needed to drive various value-capture initiatives.
So if these are the types of questions you’re asked to answer, even infrequently –then a structured contract data repository isn’t just advantageous. It’s game-changing.
Data quality: The importance of specific data accuracy
So if access to structured contract data is so valuable, how come we don’t already have it at our fingertips?
The reason, quite simply, is that turning legal prose into standardized structured data is hard. Doing so at a high level of quality and at manageable cost is exponentially harder still.
The linguistic complexity of contract prose is such that only specialized solutions aimed expressly at the challenge are consistently successful. And even the leading AI today still struggles to address the problem consistently on its own. ML can usually find text accurately, across large volumes of documents –but typically struggles to achieve satisfactory levels of accuracy on even relatively simple interpretive tasks.
Unfortunately, ‘directionally accurate’ data just isn’t good enough for most business applications. To support corporate-grade process automation, or deliver insights upon which action will be taken that impacts key commercial relationships, you need high specific accuracy.
In other words, what you need is for each individual extracted data point needs to be right. Information good enough to signal trends at the portfolio level, but which cannot reliably be tied back to specific agreements for purposes of taking real-world action, is essentially useless.
So while ML is a critical lynchpin for delivering specifically accurate data at scale, it is still very far from being able to do so on its own. It must, for the most part, be deployed in tandem with human review and validation.
To illustrate the problems that come from relying on data that hasn’t been duly validated, let’s take a look at the following example:
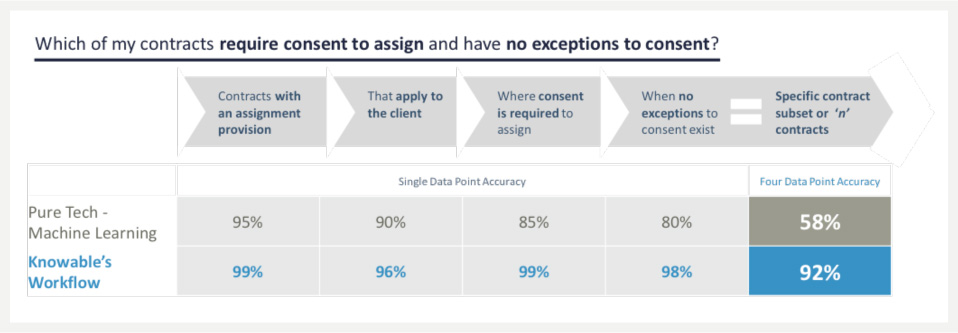
Here, we’re asking a simple question: which contracts, across our client’s portfolio, could be assigned to a 3rd party at our client’s sole discretion –an important insight in economically turbulent times such as, say, a global pandemic…
Even this simple question requires analysis of 4 separate fields. With technology-enabled human validation, it is possible to guarantee a minimum standard of accuracy for each field –here, an average of 98% field-level accuracy, which is Knowable’s typical standard. By contrast, even making generous assumptions for the level of accuracy that standalone ML models could achieve for these fields, that quality ranges from 80-95% accuracy.
The result is that, on average, trying to answer this question through technology tools alone will yield the correct answer only 58% of the time. That’s barely better than a coin flip. By contrast, the technology-enabled human-in-the-loop approach will yield the correct answer more than 90% of the time –or even higher if we choose to increase the amount of human validation introduced into the process.
Data quality: Reality vs. perception
Further compounding the problem of delivering business-ready structured contract data is the fact that, in may circumstances, the perception of data quality can be just as important as actual accuracy levels: even data that is on average of the requisite quality will fail to satisfy business users if certain particularly visible fields aren’t captured with, in essence, near-perfect accuracy.
Mistakes in those areas, even if empirically infrequent, will cause end-users to quickly lose faith in the solution as a whole. That’s understandable, in terms of both end-user psychology and what the business actually needs. But even so, the result is often still a failed deployment.
A specialized CDM solution can make all the difference here. Whereas the capability boundaries of technology are, at any given point in time, essentially immovable (i.e., if a ML model’s average accuracy is, say, 85% today, it cannot be immediately improved, or at least not without adverse tradeoffs), the right technology-enabled human-in-the-loop process can, by contrast, be easily modified to increase the level of human validation to ensure that particularly critical fields meet whatever enhanced standard is required to satisfy end-users.
Ok… So what does it take to do effective CDM?
Great question! That’s exactly what our next blog post focuses on: the capabilities that need to be deployed to deliver business-grade contracts data to the enterprise, how these are synergistic with, but also different from the key competencies of most CLM providers, and what that means for how companies should think about the order in which they build out key capabilities within their contracts ecosystem.